
一、文本情感分析(Sentiment Analysis)
所用数据为IMDB上的影评数据,它包括25000个带标签的训练数据,25000个带标签的测试数据以及50000个未带标签的数据
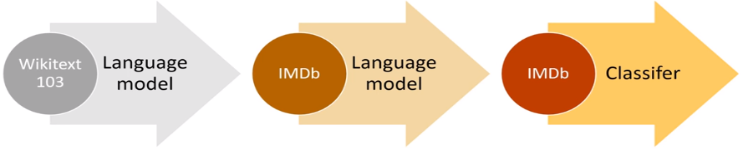
运用迁移学习的思想,首先以使用wikitext-103训练好的语言模型(预测句子中的下一个单词)为基础,使用影评数据对该语言模型进行微调,再利用微调后的模型搭建文本分类模型
from fastai.text import *
path=Path('data/imdb')
bs=48
### (1) 文本数据处理(language model)
### Use data block API for data preparation
### 1. Read, Tokenization, and Numericalization
# lower cased, split on space and punctuation symbols(punctuation symbols also treated as tokens)
# the 's are grouped together in one token, the contractions are separated(e.g., didn't --> did, n't)
# content has been cleaned for any HTML symbol
# there are several special tokens that begin by xx (e.g., xxmaj, xxup, xxunk)
# keep the tokens that appear at least twice with a maximum vocabulary size of 60,000 (by default)
# replace the remaining tokens by the unknown token UNK(i.e., xxunk)
### 2. Randomly split and keep 10% (10,000 reviews) for validation, Add a constant label for language model
data_lm = TextList.from_folder(path).filter_by_folder(include=['train', 'test', 'unsup']) \
.split_by_rand_pct(0.1).label_for_lm().databunch(bs=bs)
data_lm.save('data_lm.pkl')
### (2) 加载预训练的语言模型并进行fine-tune
learn = language_model_learner(data_lm, AWD_LSTM, drop_mult=0.3)
learn.lr_find()
learn.recorder.plot(skip_end=15)
learn.fit_one_cycle(1, 1e-2, moms=(0.8,0.7))
learn.save('fit_head')
learn.unfreeze()
learn.fit_one_cycle(10, 1e-3, moms=(0.8,0.7))
learn.save('fine_tuned')
#######################################################################################
### 使用fine-tune后的语言模型进行单词预测可以使用learn.predict(),例如:
TEXT = "I liked this movie because"
N_WORDS = 40
N_SENTENCES = 2
print("\n".join(learn.predict(TEXT, N_WORDS, temperature=0.75) for _ in range(N_SENTENCES)))
#######################################################################################
learn.save_encoder('fine_tuned_enc') #save the encoder part of language model (responsible for creating and updating the hidden state)
### (3) 文本数据处理(text classification)
### Use data block API for data preparation
### 1. Read, Tokenization, and Numericalization; Split by train and valid folder (only keeps path/train and path/test folder)
### 2. Add labels for classification model (from data folders, e.g., path/train/neg, path/train/pos)
data_clas = TextList.from_folder(path, vocab=data_lm.vocab).split_by_folder(valid='test') \
.label_from_folder(classes=['neg', 'pos']).databunch(bs=bs)
data_clas.save('data_clas.pkl')
### (4) 使用之前训练好的语言模型(encoder part)搭建文本分类模型
learn = text_classifier_learner(data_clas, AWD_LSTM, drop_mult=0.5)
learn.load_encoder('fine_tuned_enc')
learn.lr_find()
learn.recorder.plot()
learn.fit_one_cycle(1, 2e-2, moms=(0.8,0.7))
learn.save('first')
learn.freeze_to(-2) #unfreeze the last two layer groups
learn.fit_one_cycle(1, slice(1e-2/(2.6**4),1e-2), moms=(0.8,0.7))
learn.save('second')
learn.freeze_to(-3) #unfreeze the last three layer groups
learn.fit_one_cycle(1, slice(5e-3/(2.6**4),5e-3), moms=(0.8,0.7))
learn.save('third')
learn.unfreeze()
learn.fit_one_cycle(2, slice(1e-3/(2.6**4),1e-3), moms=(0.8,0.7))
learn.save('final')
### (5) 预测
learn.predict("I really loved that movie, it was awesome!") #for example