多标签分类(multi-label classification)项目(Data)
- 从卫星图片了解亚马逊雨林,每张图片可属于多个标签
F score
| 标签 | 预测为Positive(1) | 预测为Negative(0) |
|---|---|---|
| 真值为Positive(1) | TP | FN |
| 真值为Negative(0) | FP | TN |
例如真实标签是(1,0,1,1,0,0), 预测标签是(1,1,0,1,1,0), 则TP=2, FN=1, FP=2, TN=1
- 计算Precision:
- 计算Recall:
- 计算F score:
越小, F score中P的权重越大; 等于0时F score就变为P
越大, F score中R的权重越大; 趋于无穷大时F score就变为R
项目代码
from fastai.vision import *
path=Path('data/planet')
### Transformations for data augmentation
### flip_vert表示上下翻转,因为是卫星图像所以打开这一项
### max_warp是用来模拟图片拍摄时的远近和方位的不同,因为是卫星图像所以关闭这一项
tfms = get_transforms(flip_vert=True, max_lighting=0.1, max_zoom=1.05, max_warp=0.)
### Use data block API instead of ImageDataBunch for data preparation
### 1. 从对应的文件夹下读取csv文件中列出的图片名称(默认为第一列)
### 2. train/validation split 3. 读取图片对应的标签(默认为第二列)
### 4. data augmentation and resize 5. 生成DataBunch并对数据进行标准化
np.random.seed(42)
src = ImageList.from_csv(path, 'train_v2.csv', folder='train-jpg', suffix='.jpg') \
.random_split_by_pct(0.2) \
.label_from_df(label_delim=' ')
data = src.transform(tfms, size=128) \
.databunch(bs=64).normalize(imagenet_stats)
### Metrics
### 由于是多标签分类,不适合简单地使用准确率,这里采用两种评价方式
### 1. accuracy_thresh: 将分类概率大于thresh的标签设为1, 否则设为0; 同target比较计算标签的准确率
### 2. fbeta: 将分类概率大于thresh的标签设为1, 否则设为0; 计算每个样本的F score并平均
### F score的计算方法见正文部分
acc_02 = partial(accuracy_thresh, thresh=0.2)
f_score = partial(fbeta, beta=2, thresh=0.2)
### Model
arch = models.resnet50 #使用Resnet 50进行迁移学习
learn = create_cnn(data, arch, metrics=[acc_02, f_score])
learn.lr_find()
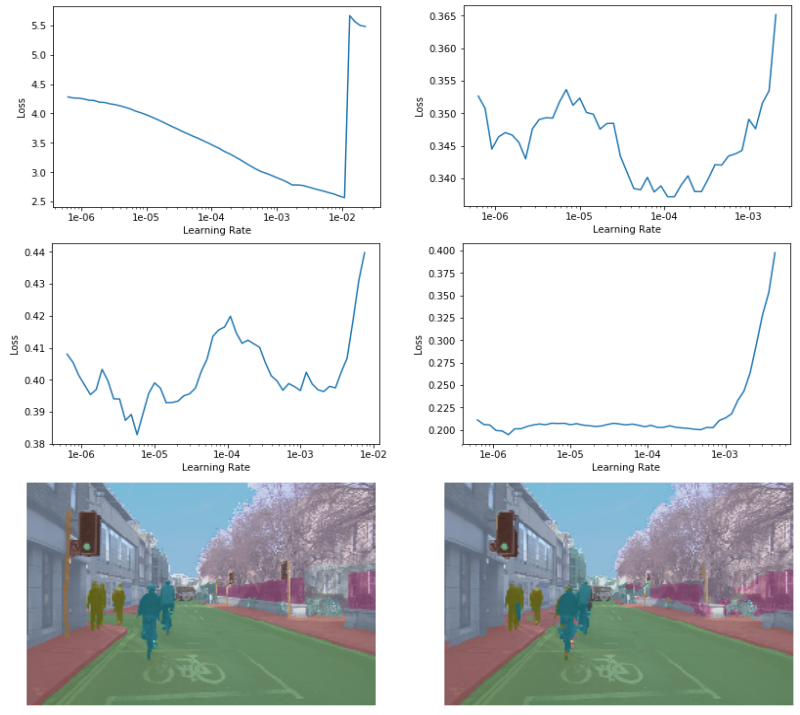
learn.recorder.plot() #左上图
lr = 0.01 #from lr_find
learn.fit_one_cycle(5, slice(lr))
learn.save('stage-1-rn50')
### Fine-tune the whole model
learn.unfreeze()
learn.lr_find()
learn.recorder.plot() #右上图
learn.fit_one_cycle(5, slice(1e-6, lr/10))
learn.save('stage-2-rn50')
### Use bigger images to train(128*128 to 256*256)
### Starting training on small images for a few epochs, then switching to bigger images,
### and continuing training is an effective way to avoid overfitting
data = src.transform(tfms, size=256).databunch(bs=32).normalize(imagenet_stats)
learn.data = data
learn.freeze()
learn.lr_find()
learn.recorder.plot() #左下图
lr=1e-3
learn.fit_one_cycle(5, slice(lr))
learn.save('stage-1-256-rn50')
learn.unfreeze()
learn.lr_find()
learn.recorder.plot() #中下图
learn.fit_one_cycle(5, slice(1e-5, lr/2))
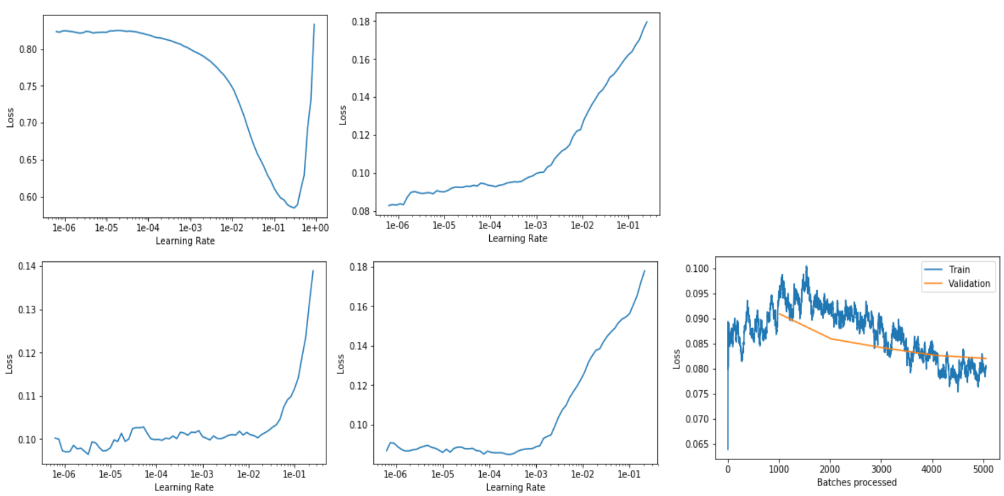
learn.recorder.plot_losses() #右下图(最近一次fit_one_cycle的train/validation loss)
learn.save('stage-2-256-rn50')
learn.export() #导出模型
图像分割(image segmentation)项目
- 使用的数据集为该Github项目中简化的CamVid数据集
项目代码
from fastai import *
from fastai.vision import *
from fastai.callbacks.hooks import *
path = Path('./CamVid')
src_size = np.array([360, 480]) #original image size
### get mask image file name from original image file name
### e.g., ./CamVid/val/0016E5_08085.png--> ./CamVid/valannot/0016E5_08085.png
def get_y_fn(x): return Path(str(x.parent)+'annot')/x.name
codes = array(['Sky', 'Building', 'Pole', 'Road', 'Sidewalk', 'Tree', \
'Sign', 'Fence', 'Car', 'Pedestrian', 'Cyclist', 'Void']) #mask code
bs, size = 8, src_size//2
### Use data block API for data preparation
### 1. 从path及其子文件夹下搜索图片文件
### 2. train/validation split(path/train, path/val)
### 3. 从原始图片得到mask图片作为标签
### 4. data augmentation and resize(tfm_y: 标签是否同样进行转换)
### 5. 生成DataBunch并对数据进行标准化
src = SegmentationItemList.from_folder(path).split_by_folder(valid='val') \
.label_from_func(get_y_fn, classes=codes)
data = src.transform(get_transforms(), size=size, tfm_y=True) \
.databunch(bs=bs).normalize(imagenet_stats)
data.show_batch(2, figsize=(10,7)) #display
### Accuracy function
### 去掉标记为‘Void’的像素点之后再计算准确率
### input: (bs, len(codes), 180, 240); target: (bs, 1, 180, 240)
name2id = {v:k for k,v in enumerate(codes)}
void_code = name2id['Void']
def acc_camvid(input, target):
target = target.squeeze(1) #(bs, 1, 180, 240)-->(bs, 180, 240)
mask = target != void_code
return (input.argmax(dim=1)[mask]==target[mask]).float().mean()
metrics=acc_camvid
### Unet Model
wd=1e-2 #weight decay
learn = unet_learner(data, models.resnet34, metrics=metrics, wd=wd, bottle=True)
lr_find(learn)
learn.recorder.plot() #左上图
lr=2e-3 #from lr_find
learn.fit_one_cycle(10, slice(lr), pct_start=0.8)
learn.save('stage-1')
learn.unfreeze() #fine-tune the whole model
lr_find(learn)
learn.recorder.plot() #右上图
lrs = slice(lr/100,lr) #from lr_find
learn.fit_one_cycle(12, lrs, pct_start=0.8)
learn.save('stage-2')
### Use bigger images to train
learn=None
gc.collect() #clear memory
bs, size = 4, src_size
data = src.transform(get_transforms(), size=size, tfm_y=True) \
.databunch(bs=bs).normalize(imagenet_stats)
learn = unet_learner(data, models.resnet34, metrics=metrics, wd=wd, bottle=True).load('stage-2')
lr_find(learn)
learn.recorder.plot() #左中图
lr=3e-4
learn.fit_one_cycle(10, slice(lr), pct_start=0.8)
learn.save('stage-1-big')
learn.unfreeze()
lr_find(learn)
learn.recorder.plot() #右中图
lrs = slice(1e-6,lr/3)
learn.fit_one_cycle(10, lrs)
learn.save('stage-2-big')
learn.show_results(rows=1, figsize=(9,4)) #左下图为真实值, 右下图为预测值