参考文章(Reference Blog)
数据下载(Data Download)
数据说明(Data Introduction)
数据前处理
- 导入数据
import pandas as pd import numpy as np from sklearn.cross_validation import train_test_split ### Load data ### Split the data to train and test sets data = pd.read_csv('data/loan/Train.csv', encoding = "ISO-8859-1") train, test = train_test_split(data,train_size=0.7,random_state=123,stratify=data['Disbursed']) ### Check number of nulls in each feature column nulls_per_column = train.isnull().sum() print(nulls_per_column) - 将特征拆分成数值型和种类型
### Drop the useless columns train_1 = train.drop(['ID','Lead_Creation_Date','LoggedIn'],axis=1) ### Split the columns to numerical and categorical category_cols = train_1.columns[train_1.dtypes==object].tolist() category_cols.remove('DOB') category_cols.append('Var4') numeric_cols = list(set(train_1.columns)-set(category_cols)) - 分析并处理种类型特征
### explore the categorical columns for v in category_cols: print('Ratio of missing value for variable {0}: {1}'.format(v,nulls_per_column[v]/train_1.shape[0])) print('-----------------------------------------------------------') counts = dict() for v in category_cols: print('\nFrequency count for variable %s'%v) counts[v] = train_1[v].value_counts() print(counts[v]) ### merge the cities that counts<200 merge_city = [c for c in counts['City'].index if counts['City'][c]<200] train_1['City'] = train_1['City'].apply(lambda x: 'others' if x in merge_city else x) ### merge the salary accounts that counts<100 merge_sa = [c for c in counts['Salary_Account'].index if counts['Salary_Account'][c]<100] train_1['Salary_Account'] = train_1['Salary_Account'].apply(lambda x: 'others' if x in merge_sa else x) ### merge the sources that counts<100 merge_sr = [c for c in counts['Source'].index if counts['Source'][c]<100] train_1['Source'] = train_1['Source'].apply(lambda x: 'others' if x in merge_sr else x) ### impute the missing value train_1['City'].fillna('Missing',inplace=True) train_1['Salary_Account'].fillna('Missing',inplace=True) ### delete the column Employer_Name since too many categories train_2 = train_1.drop('Employer_Name',axis=1) - 分析并处理数值型特征
### Explore the numerical columns for v in numeric_cols: print('Ratio of missing value for variable {0}: {1}'.format(v,nulls_per_column[v]/train_2.shape[0])) print('-----------------------------------------------------------') for v in numeric_cols: print('\nStatistical summary for variable %s'%v) print(train_2[v].describe()) ### Create Age column: train_2['Age'] = train_2['DOB'].apply(lambda x: 118 - int(x[-2:])) ### High proportion missing so create a new variable stating whether this is missing or not: train_2['Loan_Amount_Submitted_Missing'] = train_2['Loan_Amount_Submitted'].apply(lambda x: 1 if pd.isnull(x) else 0) train_2['Loan_Tenure_Submitted_Missing'] = train_2['Loan_Tenure_Submitted'].apply(lambda x: 1 if pd.isnull(x) else 0) train_2['EMI_Loan_Submitted_Missing'] = train_2['EMI_Loan_Submitted'].apply(lambda x: 1 if pd.isnull(x) else 0) train_2['Interest_Rate_Missing'] = train_2['Interest_Rate'].apply(lambda x: 1 if pd.isnull(x) else 0) train_2['Processing_Fee_Missing'] = train_2['Processing_Fee'].apply(lambda x: 1 if pd.isnull(x) else 0) ### Impute the missing value train_2['Existing_EMI'].fillna(train_2['Existing_EMI'].median(), inplace=True) train_2['Loan_Amount_Applied'].fillna(train_2['Loan_Amount_Applied'].median(),inplace=True) train_2['Loan_Tenure_Applied'].fillna(train_2['Loan_Tenure_Applied'].median(),inplace=True) ### Drop original columns train_3 = train_2.drop(['DOB','Loan_Amount_Submitted','Loan_Tenure_Submitted','EMI_Loan_Submitted', \ 'Interest_Rate','Processing_Fee'],axis=1) - One-Hot encoding
from sklearn.preprocessing import LabelEncoder dropped_columns = ['ID','Lead_Creation_Date','LoggedIn','Employer_Name','DOB','Loan_Amount_Submitted', \ 'Loan_Tenure_Submitted','EMI_Loan_Submitted','Interest_Rate','Processing_Fee'] le = LabelEncoder() var_to_encode = list(set(category_cols)-set(dropped_columns)) for col in var_to_encode: train_3[col] = le.fit_transform(train_3[col]) ### pd.get_dummies can also be used directly without LabelEncoder train_3 = pd.get_dummies(train_3, columns=var_to_encode)
模型调参
- 建立基础模型并使用early_stop调整迭代次数
import xgboost as xgb import matplotlib.pyplot as plt from sklearn import metrics ### base model target = 'Disbursed' predictors = [x for x in train_3.columns if x!=target] xgb1 = xgb.XGBClassifier(learning_rate=0.1, n_estimators=1000, max_depth=5, min_child_weight=1, gamma=0, \ subsample=0.8, colsample_bytree=0.8, objective= 'binary:logistic', nthread=4, seed=27) ### use early_stop in xgb.cv def get_n_estimators(alg, dtrain, predictors, target, cv_folds=5, early_stopping_rounds=50): xgb_param = alg.get_xgb_params() xgtrain = xgb.DMatrix(dtrain[predictors], label=dtrain[target]) cvresult = xgb.cv(xgb_param, xgtrain, num_boost_round=alg.get_params()['n_estimators'], nfold=cv_folds, \ metrics='auc', early_stopping_rounds=early_stopping_rounds, stratified=True) alg.set_params(n_estimators=cvresult.shape[0]) #Print model report: print("\nModel Report") print("Set n_estimators to {0}".format(cvresult.shape[0])) print(cvresult.tail(1)['test-auc-mean']) #Fit the algorithm on the data alg.fit(dtrain[predictors], dtrain[target], eval_metric='auc') #Feature importance feat_imp = pd.Series(alg.get_booster().get_fscore()).sort_values(ascending=False) feat_imp.plot(kind='bar', title='Feature Importances', figsize=(20,6)) plt.ylabel('Feature Importance Score') return ### get n_estimators get_n_estimators(xgb1, train_3, predictors, target) - Tune max_depth and min_child_weight
from sklearn.model_selection import GridSearchCV ### optimal: {'max_depth':5,'min_child_weight':5} param_test1 = {'max_depth':range(3,10,2),'min_child_weight':range(1,6,2)} alg = xgb.XGBClassifier(learning_rate=0.1, n_estimators=141, max_depth=5, min_child_weight=1, gamma=0, \ subsample=0.8, colsample_bytree=0.8, objective= 'binary:logistic', nthread=4, seed=27) gsearch1 = GridSearchCV(estimator = alg, param_grid = param_test1, scoring='roc_auc', n_jobs=4, iid=False, cv=5) gsearch1.fit(train_3[predictors],train_3[target]) print(gsearch1.best_params_) print(gsearch1.best_score_) ### optimal: {'max_depth':4,'min_child_weight':6} param_test2 = {'max_depth':[4,5,6],'min_child_weight':[4,5,6]} alg = xgb.XGBClassifier(learning_rate=0.1, n_estimators=141, max_depth=5, min_child_weight=5, gamma=0, \ subsample=0.8, colsample_bytree=0.8, objective= 'binary:logistic', nthread=4, seed=27) gsearch2 = GridSearchCV(estimator = alg, param_grid = param_test2, scoring='roc_auc', n_jobs=4, iid=False, cv=5) gsearch2.fit(train_3[predictors],train_3[target]) print(gsearch2.best_params_) print(gsearch2.best_score_) ### optimal: {'min_child_weight':6} param_test2b = {'min_child_weight':[6,8,10,12]} alg = xgb.XGBClassifier(learning_rate=0.1, n_estimators=141, max_depth=4, min_child_weight=6, gamma=0, \ subsample=0.8, colsample_bytree=0.8, objective= 'binary:logistic', nthread=4, seed=27) gsearch2b = GridSearchCV(estimator = alg, param_grid = param_test2b, scoring='roc_auc', n_jobs=4, iid=False, cv=5) gsearch2b.fit(train_3[predictors],train_3[target]) print(gsearch2b.best_params_) print(gsearch2b.best_score_) - Tune gamma
### optimal: {'gamma':0.2} param_test3 = {'gamma':[i/10.0 for i in range(0,5)]} alg = xgb.XGBClassifier(learning_rate=0.1, n_estimators=141, max_depth=4, min_child_weight=6, gamma=0, \ subsample=0.8, colsample_bytree=0.8, objective= 'binary:logistic', nthread=4, seed=27) gsearch3 = GridSearchCV(estimator = alg, param_grid = param_test3, scoring='roc_auc', n_jobs=4, iid=False, cv=5) gsearch3.fit(train_3[predictors],train_3[target]) print(gsearch3.best_params_) print(gsearch3.best_score_) ### get n_estimators xgb2 = xgb.XGBClassifier(learning_rate=0.1, n_estimators=1000, max_depth=4, min_child_weight=6, gamma=0.2, \ subsample=0.8, colsample_bytree=0.8, objective= 'binary:logistic', nthread=4, seed=27) get_n_estimators(xgb2, train_3, predictors, target) - Tune subsample and colsample_bytree
### optimal: {'colsample_bytree': 0.7, 'subsample': 0.7} param_test4 = {'subsample':[i/10.0 for i in range(6,11)], 'colsample_bytree':[i/10.0 for i in range(6,11)]} alg = xgb.XGBClassifier(learning_rate=0.1, n_estimators=142, max_depth=4, min_child_weight=6, gamma=0.2, \ subsample=0.8, colsample_bytree=0.8, objective= 'binary:logistic', nthread=4, seed=27) gsearch4 = GridSearchCV(estimator = alg, param_grid = param_test4, scoring='roc_auc', n_jobs=4, iid=False, cv=5) gsearch4.fit(train_3[predictors],train_3[target]) print(gsearch4.best_params_) print(gsearch4.best_score_) ### optimal: {'colsample_bytree': 0.75, 'subsample': 0.7} param_test5 = {'subsample':[i/100.0 for i in range(65,80,5)], 'colsample_bytree':[i/100.0 for i in range(65,80,5)]} alg = xgb.XGBClassifier(learning_rate=0.1, n_estimators=142, max_depth=4, min_child_weight=6, gamma=0.2, \ subsample=0.7, colsample_bytree=0.7, objective= 'binary:logistic', nthread=4, seed=27) gsearch5 = GridSearchCV(estimator = alg, param_grid = param_test5, scoring='roc_auc', n_jobs=4, iid=False, cv=5) gsearch5.fit(train_3[predictors],train_3[target]) print(gsearch5.best_params_) print(gsearch5.best_score_) - Tune reg_alpha
### optimal: {'reg_alpha': 0.01} param_test6 = {'reg_alpha':[0, 1e-5, 1e-2, 0.1, 1, 100]} alg = xgb.XGBClassifier(learning_rate=0.1, n_estimators=142, max_depth=4, min_child_weight=6, gamma=0.2, \ subsample=0.7, colsample_bytree=0.75, objective= 'binary:logistic', nthread=4, seed=27) gsearch6 = GridSearchCV(estimator = alg, param_grid = param_test6, scoring='roc_auc', n_jobs=4, iid=False, cv=5) gsearch6.fit(train_3[predictors],train_3[target]) print(gsearch6.best_params_) print(gsearch6.best_score_) ### optimal: {'reg_alpha': 0.01} param_test7 = {'reg_alpha':[0.001, 0.005, 0.01, 0.05]} alg = xgb.XGBClassifier(learning_rate=0.1, n_estimators=142, max_depth=4, min_child_weight=6, gamma=0.2, reg_alpha=0.01, \ subsample=0.7, colsample_bytree=0.75, objective= 'binary:logistic', nthread=4, seed=27) gsearch7 = GridSearchCV(estimator = alg, param_grid = param_test7, scoring='roc_auc', n_jobs=4, iid=False, cv=5) gsearch7.fit(train_3[predictors],train_3[target]) print(gsearch7.best_params_) print(gsearch7.best_score_) - Tune reg_lambda
### optimal: {'reg_lambda': 1} param_test8 = {'reg_lambda':[0, 0.01, 0.1, 1, 10, 100]} alg = xgb.XGBClassifier(learning_rate=0.1, n_estimators=142, max_depth=4, min_child_weight=6, gamma=0.2, reg_alpha=0.01, \ subsample=0.7, colsample_bytree=0.75, objective= 'binary:logistic', nthread=4, seed=27) gsearch8 = GridSearchCV(estimator = alg, param_grid = param_test8, scoring='roc_auc', n_jobs=4, iid=False, cv=5) gsearch8.fit(train_3[predictors],train_3[target]) print(gsearch8.best_params_) print(gsearch8.best_score_) ### optimal: {'reg_lambda': 1} param_test9 = {'reg_lambda':[0.5, 0.7, 1, 3, 5]} alg = xgb.XGBClassifier(learning_rate=0.1, n_estimators=142, max_depth=4, min_child_weight=6, gamma=0.2, reg_alpha=0.01, \ subsample=0.7, colsample_bytree=0.75, objective= 'binary:logistic', nthread=4, seed=27) gsearch9 = GridSearchCV(estimator = alg, param_grid = param_test9, scoring='roc_auc', n_jobs=4, iid=False, cv=5) gsearch9.fit(train_3[predictors],train_3[target]) print(gsearch9.best_params_) print(gsearch9.best_score_) ### get n_estimators xgb3 = xgb.XGBClassifier(learning_rate=0.1, n_estimators=1000, max_depth=4, min_child_weight=6, gamma=0.2, \ reg_alpha=0.01, reg_lambda=1, subsample=0.7, colsample_bytree=0.75, \ objective= 'binary:logistic', nthread=4, seed=27) get_n_estimators(xgb3, train_3, predictors, target) - Reduce learning rate
xgb4 = xgb.XGBClassifier(learning_rate=0.01, n_estimators=5000, max_depth=4, min_child_weight=6, gamma=0.2, \ reg_alpha=0.01, reg_lambda=1, subsample=0.7, colsample_bytree=0.75, \ objective= 'binary:logistic', nthread=4, seed=27) get_n_estimators(xgb4, train_3, predictors, target)
根据上述过程构建最终的Pipeline
import pandas as pd
import numpy as np
import xgboost as xgb
import matplotlib.pyplot as plt
from sklearn import metrics
from sklearn.cross_validation import train_test_split
from sklearn.feature_extraction import DictVectorizer
from sklearn.preprocessing import Imputer, FunctionTransformer
from sklearn_pandas import DataFrameMapper, CategoricalImputer
from sklearn.pipeline import FeatureUnion, Pipeline
data = pd.read_csv('data/loan/Train.csv', encoding = "ISO-8859-1")
train, test = train_test_split(data,train_size=0.7,random_state=123,stratify=data['Disbursed'])
target_raw = 'Disbursed'
predictors_raw = [col for col in train.columns if col!=target_raw]
train_X, train_y = train[predictors_raw], train[target_raw]
category_cols = train_X.columns[train_X.dtypes==object].tolist()
category_cols.remove('DOB')
category_cols.append('Var4')
numeric_cols = list(set(train_X.columns)-set(category_cols))
numeric_cols = numeric_cols+['Age', 'Loan_Amount_Submitted_Missing', 'Loan_Tenure_Submitted_Missing', \
'EMI_Loan_Submitted_Missing', 'Interest_Rate_Missing', 'Processing_Fee_Missing']
counts = dict()
for v in category_cols:
counts[v] = train_X[v].value_counts()
non_merge_city = [c for c in counts['City'].index if counts['City'][c]>=200]
non_merge_sa = [c for c in counts['Salary_Account'].index if counts['Salary_Account'][c]>=100]
non_merge_sr = [c for c in counts['Source'].index if counts['Source'][c]>=100]
dropped_columns = ['ID','Lead_Creation_Date','LoggedIn','Employer_Name','DOB','Loan_Amount_Submitted', \
'Loan_Tenure_Submitted','EMI_Loan_Submitted','Interest_Rate','Processing_Fee']
def preprocess(X):
X['City'] = X['City'].apply(lambda x: 'others' if x not in non_merge_city and not pd.isnull(x) else x)
X['Salary_Account'] = X['Salary_Account'].apply(lambda x: 'others' if x not in non_merge_sa and not pd.isnull(x) else x)
X['Source'] = X['Source'].apply(lambda x: 'others' if x not in non_merge_sr and not pd.isnull(x) else x)
X['Age'] = X['DOB'].apply(lambda x: 118 - int(x[-2:]))
X['Loan_Amount_Submitted_Missing'] = X['Loan_Amount_Submitted'].apply(lambda x: 1 if pd.isnull(x) else 0)
X['Loan_Tenure_Submitted_Missing'] = X['Loan_Tenure_Submitted'].apply(lambda x: 1 if pd.isnull(x) else 0)
X['EMI_Loan_Submitted_Missing'] = X['EMI_Loan_Submitted'].apply(lambda x: 1 if pd.isnull(x) else 0)
X['Interest_Rate_Missing'] = X['Interest_Rate'].apply(lambda x: 1 if pd.isnull(x) else 0)
X['Processing_Fee_Missing'] = X['Processing_Fee'].apply(lambda x: 1 if pd.isnull(x) else 0)
return X.drop(dropped_columns, axis=1)
# Apply numeric imputer
numeric_imputer = [([feature], Imputer(strategy="median")) for feature in numeric_cols if feature not in dropped_columns]
numeric_imputation_mapper = DataFrameMapper(numeric_imputer, input_df=True, df_out=True)
# Apply categorical imputer
category_imputer = [(feature, CategoricalImputer(strategy='fixed_value', replacement='Missing')) \
for feature in category_cols if feature not in dropped_columns]
categorical_imputation_mapper = DataFrameMapper(category_imputer,input_df=True,df_out=True)
# Combine the numeric and categorical transformations
numeric_categorical_union = FeatureUnion([("num_mapper", numeric_imputation_mapper), \
("cat_mapper", categorical_imputation_mapper)])
def dictify(X):
col_1 = [feature for feature in numeric_cols if feature not in dropped_columns]
col_2 = [feature for feature in category_cols if feature not in dropped_columns]
X_numeric = pd.DataFrame(X[:,0:len(col_1)], columns=col_1, dtype='float')
X_category = pd.DataFrame(X[:,len(col_1):], columns=col_2, dtype='str')
return pd.concat([X_numeric,X_category], axis=1).to_dict("records")
tuned_xgb = xgb.XGBClassifier(learning_rate=0.01, n_estimators=1480, max_depth=4, min_child_weight=6, gamma=0.2, \
reg_alpha=0.01, reg_lambda=1, subsample=0.7, colsample_bytree=0.75, \
objective= 'binary:logistic', nthread=4, seed=27)
# Create full pipeline
pipeline = Pipeline([("preprocessor", FunctionTransformer(preprocess, validate=False)), \
("featureunion", numeric_categorical_union), ("dictifier", FunctionTransformer(dictify, validate=False)), \
("onehot", DictVectorizer(sparse=False)), ("classifier", tuned_xgb)])
pipeline.fit(train_X, train_y)
#Feature importance
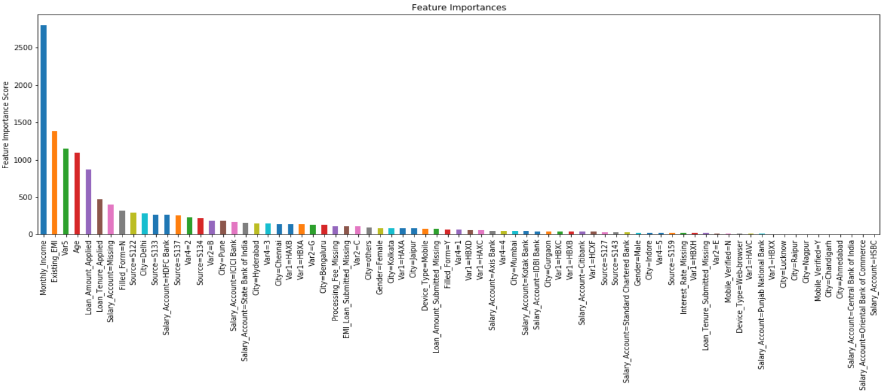
feat_imp = pd.Series(pipeline.named_steps['classifier'].get_booster().get_fscore()).sort_values(ascending=False)
features = [pipeline.named_steps['onehot'].feature_names_[int(i[1:])] for i in feat_imp.index]
fig = feat_imp.plot(kind='bar', title='Feature Importances', figsize=(20,6)) #下图
fig.set_xticklabels(features)
fig.set_ylabel('Feature Importance Score')
# individual prediction
print(pipeline.predict_proba(test.iloc[[1]][predictors_raw]))
# test data predictions
# AUC Score (Test): 0.8568
predprob=pipeline.predict_proba(test[predictors_raw])[:,1]
print("AUC Score (Test): %f" % metrics.roc_auc_score(test[target_raw], predprob))